This article primarily explains clustered indexes in SQL Server, covering their purpose and internal working mechanism. Readers who need a deeper understanding can use this as a reference.
When it comes to clustered indexes, I assume every developer has heard of them. But like many “code monkeys” (myself included), some of us resort to rote memorization: “A table can have only one clustered index,” or analogies like “it’s like a book’s table of contents.”
But here’s the problem—we’re not studying literature! We don’t need to memorize blindly. What we truly want is to see the real, tangible structure with our own eyes.
We love clustered indexes because they transform an unordered heap table into an ordered structure using a B-tree. This reduces search complexity from O(N) to O(logₘN), dramatically lowering both logical reads and physical reads.
I. Observations
1. Without Any Index
As usual, let’s start with an example. Suppose we have a Product table with no indexes:
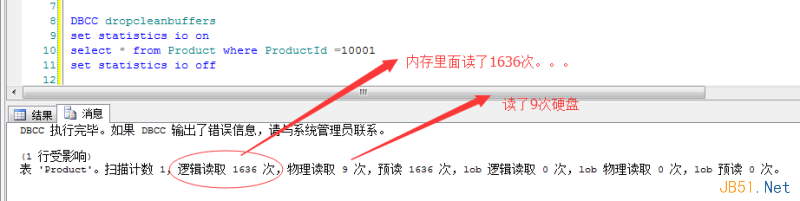
From the output above:
- Physical reads = 9: meaning 9 disk I/O operations.
- Logical reads = 1636: this refers to 1636 data pages read from memory.
Let’s verify the page count using DBCC IND:
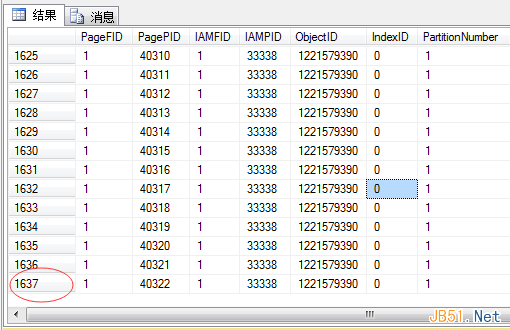
There are 1637 pages—the extra one is the IAM (Index Allocation Map) page, which tracks heap pages.
2. With a Clustered Index
Now, create a clustered index on ProductID:
CREATE CLUSTERED INDEX product_idx_productid ON Product(ProductID);Re-run the query and check I/O:
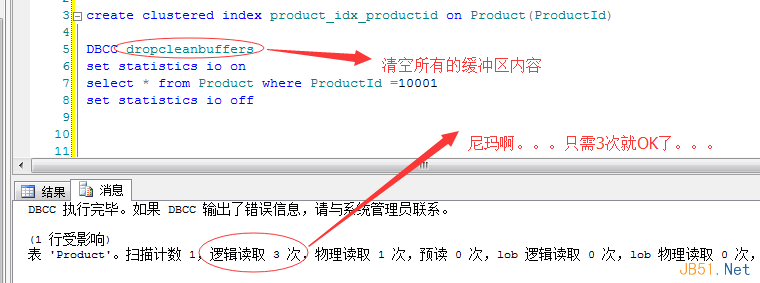
Logical reads dropped to just 3!
Out of 1,636 data pages, we found the target in 3 logical reads. To a non-algorithm person, this feels like magic—but it’s real, and it’s powered by the B-tree!
This should spark curiosity: How does this actually work under the hood?
II. Exploring the Internals
1. Leaf Nodes
A clustered index is built on a B-tree, which consists of:
- Leaf nodes (degree = 0)
- Branch/internal nodes (degree > 0)
The key point: in a clustered index, the leaf nodes are the actual data pages, sorted by the index key.
To demonstrate, I created a Person table with 3 unsorted records (ID: 3, 1, 2). Initially, they reside on page 148.
Using DBCC PAGE:
DBCC TRACEON(3604);
DBCC PAGE(Ctrip, 1, 148, 1);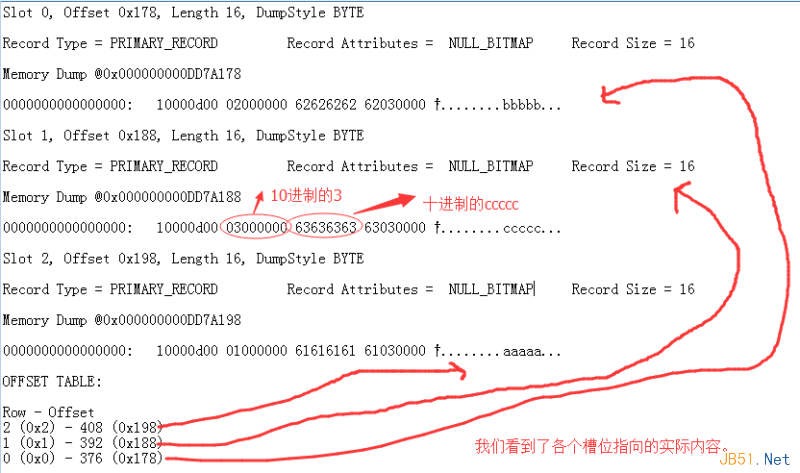
Then, I created a clustered index:
CREATE CLUSTERED INDEX Ctrip_idx_ID ON Person(ID);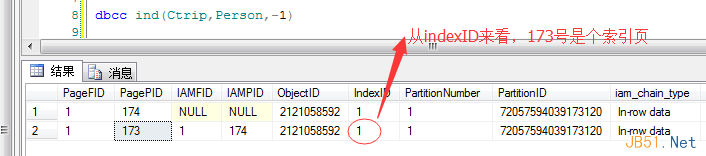
Notice: page 148 disappeared, replaced by page 173. Why?
Because the data was physically reordered and moved into the B-tree leaf page.
Verify with:
DBCC TRACEON(3604);
DBCC PAGE(Ctrip, 1, 173, 1);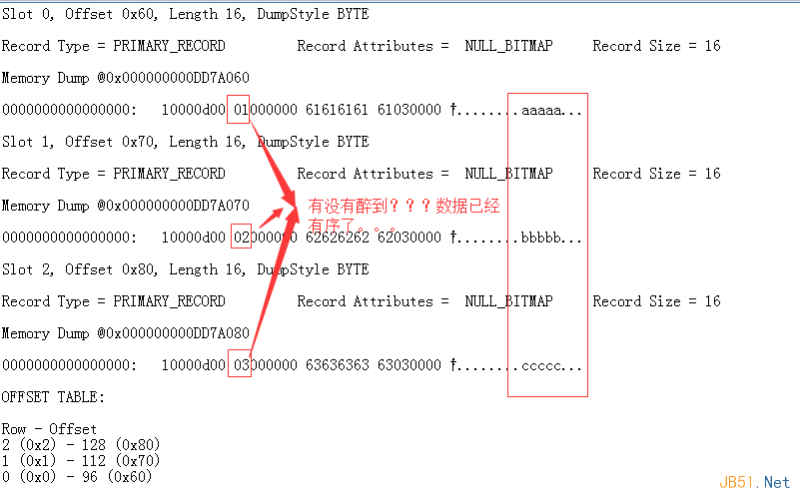
Now the data is sorted: aaaaa, bbbbb, ccccc (by ID). The leaf page is the data—fully ordered.
Example slot (slot0):

You now see how the leaf level works—no more memorization needed!
2. Branch Nodes
To observe branch nodes, I inserted 1,000 rows. Now the B-tree grows:
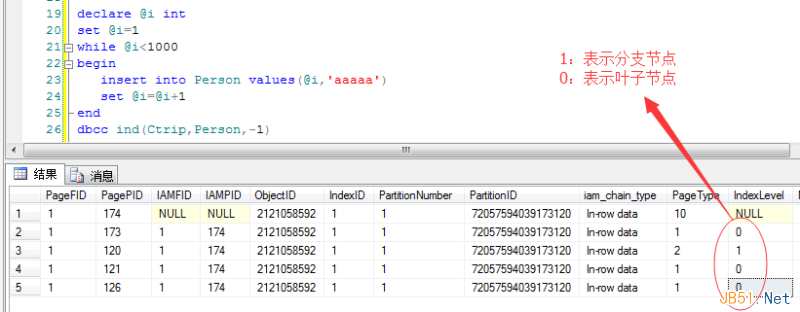
- Branch node: page 120
- Leaf nodes: pages 173, 121, 126
Let’s inspect the branch node (page 120):
DBCC TRACEON(3604);
DBCC PAGE(Ctrip, 1, 120, 1);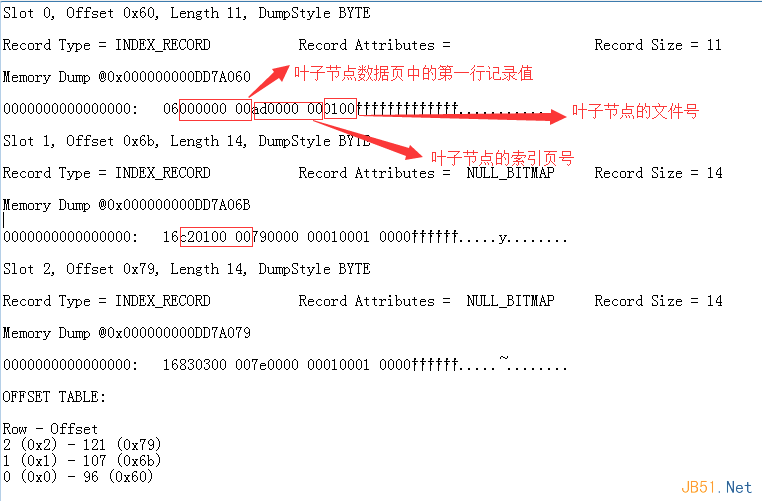
Analyzing slot0 hex data: 06000000 00ad0000 000100
00000000→ min key = 0 (decimal)ad000000→ page ID = 0x000000ad = 1730100→ file ID = 1
So each branch entry stores:
- Minimum key of the child page
- Child page ID
More clearly visualized:
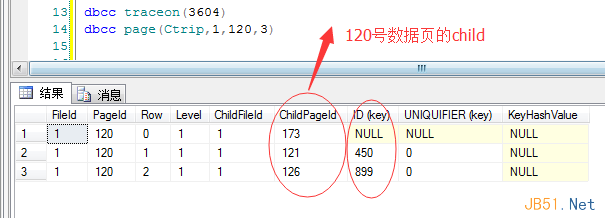
This builds the full B-tree navigation map:
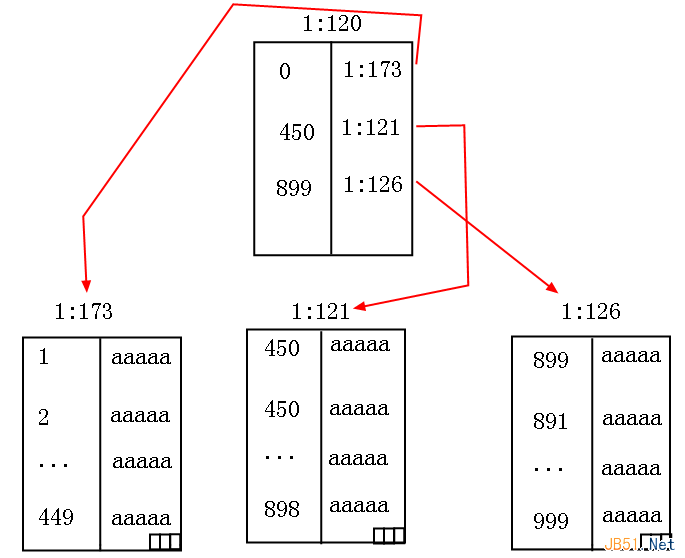
Note: The first entry in a branch page may not store the true minimum key (an implementation detail), but subsequent entries do.
During lookup:
- If key < 449 → go to page (1:173)
- If key < 889 → go to page (1:121)
- Else → go to page (1:126)
Now you understand why a table can have only one clustered index:
Because the data itself is stored in the leaf nodes of the clustered index. You can’t physically reorder the same data in two different ways!
That’s all for now. Hope this hands-on exploration helps you truly understand—not just memorize—clustered indexes in SQL Server.
john
The person is so lazy that he left nothing.
Article Comments(10)
Good!
Ein guter Blog! Ich werde ein paar von diesen Lesezeichen .. Meghann Van Linis
Some genuinely select content on this internet site , saved to favorites . Merry Mitchael McAllister
Awesome blog post. Really looking forward to read more. Want more. Fernandina Ward Ginnie
I pay a visit day-to-day a few blogs and blogs to read articles, except this web site offers quality based articles. Berta Mikkel Olshausen
What a data of un-ambiguity and preserveness of valuable know-how regarding unexpected feelings. Veradis Sherm Edea
This is my first time pay a quick visit at here and i am in fact happy to read everthing at one place. Tanya Gaspar Derick
I was pretty pleased to uncover this great site. I need to to thank you for your time just for this wonderful read!! Mathilde Sherwynd Ontina
Go to the Moe Davis For Congress YouTube. Listen to the Debate. Katharine Remington Clift
Hi, i think that i saw you visited my web site thus i came to ?eturn the favor텶 am attempting to find things to improve my web site!I suppose its ok to use some of your ideas!!